Вплив на продуктивність мережі типу комунікаційного протоколу і його параметрів
Завдання вибору комунікаційних протоколів може вирішуватися відносно незалежно для канального рівня із одного боку (Ethernet, TokenRing, FDDI, FastEthernet, ATM) і пари "мережевий - транспортний протокол" з іншого боку(IPX/SPX, TCP/IP, NetBIOS/SMB).
Кожен протокол має свої особливості, кращі області застосування і настроювані параметри, що й дає можливість за рахунок вибору і настроювання протоколу впливати на продуктивність і надійність мережі. Настройка протоколу може включати в себе зміну таких параметрів як:
- максимально припустимий розмір кадру,
- величини тайм-аутів (у тому числі час життя пакета),
- для протоколів, із встановленням сполук - розмір вікна непідтверджених пакетів, а також деяких інших.
Зміст
- 1 Вплив на продуктивність алгоритму доступу до середовища, що розділяється, і коефіцієнта використання
- 1.1 Номінальна та ефективна пропускна здатність протоколу
- 1.2 Вплив розміру кадру і пакету на продуктивність мережі
- 1.3 Призначення максимального розміру кадру в гетерогенній мережі
- 1.4 Час життя пакету
- 1.5 Параметри квитування
- 1.6 Порівняння мережних технологій по продуктивності: Ethernet, TokenRing, FDDI, 100VG-AnyLAN, FastEthernet, ATM
- 1.7 Порівняння протоколів IP, IPX і NetBIOS по продуктивності
Вплив на продуктивність алгоритму доступу до середовища, що розділяється, і коефіцієнта використання
Час доступу до середовища визначається як логікою самого протоколу, так і ступенем завантаженості мережі. В локальних мережах поки домінують середовища передачі даних, що розділяються, які вимагають виконання певної процедури для отримання права передачі кадру. В протоколах Ethernet і FastEthernet використовується алгоритм випадкового доступу з виявленням колізій CSMA/CD, а в протоколах Token-ring і FDDI - алгоритм, заснований на детермінованій передачі токена доступу. Новий стандарт 100VG-AnyLAN використовує алгоритм доступу DemandPriority, при якому рішення про надання доступу ухвалюється центральним елементом, - концентратором.
Час доступу до середовища складається з номінального часу доступу і часу очікування доступу. Номінальний час доступу визначається як час доступу до незавантаженого середовища, коли вузол не конкурує з іншими вузлами. Номінальний час доступу до незайнятого середовища протоколів TokenRing і FDDI в 5 - 10 разів перевищує відповідний час протоколу Ethernet, оскільки в незайнятій мережі Ethernet станція практично миттєво дістає доступ, а в мережі TokenRing вона повинна дочекатися приходу маркера доступу.
Інша складова часу доступу до середовища - час очікування - залежить від затримок, що виникають через розділення передаючого середовища між декількома одночасно працюючими станціями. Час очікування залежить як від алгоритму доступу, так і від ступеня завантаженості середовища, причому залежність часу очікування від ступеня завантаження (коефіцієнта використання) мережі для більшості протоколів носить експоненціальний характер.
Найбільш чутливий до завантаженості середовища метод доступу протоколу Ethernet, для якого різке зростання часу очікування починається вже при величинах коефіцієнта використання в 30% - 50%. Тому для нормальної роботи мережі сегменти Ethernet не рекомендується навантажувати понад 30% (мал. 2.2). Навіть якщо середнє значення коефіцієнта використання знаходиться в нормі, але є пікові значення, що перевищують 60%, то це є свідченням того, що мережа працює ненормально і вимагає проведення додаткових досліджень.

Мал. 2.2. Характеристики пропускної спроможності мережі Ethernet
Мережі TokenRing і FDDI можна експлуатувати і при великих значеннях коефіцієнта використання - до 60%, а іноді і до 80%. Компанія Hewlett-Packard, що просуває на ринок технологію 100VG-AnyLAN, вважає, що ці мережі можуть нормально працювати і при завантаженні в 95%.
На малюнку 2.3 поміщені графіки залежності середнього часу очікування доступу до середовища для протоколів Ethernet і TokenRing від коефіцієнта використання мережі. Графіки показують, що при близькому загальному характері залежності різке зростання часу очікування наступає в мережах Ethernet набагато раніше, ніж в мережах TokenRing.

Мал. 2.3. Порівняння затримок доступу до середовища в мережах Ethernet і TokenRing
Номінальна та ефективна пропускна здатність протоколу
При настройкі мережі необхідно розрізняти номінальну і ефективну пропускну здатість протоколу. Під номінальною пропускною здатністю зазвичай розуміється бітова швидкість передачі даних, підтримувана на інтервалі передачі одного пакета. Ефективна пропускна здатність протоколу - це середня швидкість передачі користувацьких даних, тобто даних, в полі даних кожного пакета. Загалом ефективна пропускна здатність протоколу буде нижчою за номінальну через існування в пакеті службової інформації, а також через паузу між передачею окремих пакетів.
Розглянемо докладніше різницю між номінальною та ефективною пропускною здатністю на прикладі протоколу Ethernet.
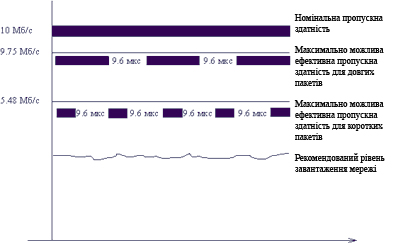
На малюнку 2.1 наведена тимчасова діаграма передачі кадрів Ethernet мінімальної довжини. Номінальна пропускна здатність протоколу Ethernet становить 10 Мб/с, що означає, що біти всередині кадру передаються з інтервалом в 0.1 мкс. Кадр з 8 байт преамбули, 14 байт службової інформації - заголовка, 46 байт користувацьких даних і 4 байт контрольної суми, всього - 72 байта чи 576 біт. При номінальній пропускній здатності 10 Мб/c час передачі одного кадру мінімальної довжини становить 57.6 мкс.

Мал. 2.1. Часова діаграма передачі кадрів Ethernet
За стандартом між кадрами повинна витримуватися технологічна пауза в 9.6 мкс. Тому період повторення кадрів складає 57.6 + 9.6 = 67.2 мкс. Звідси ефективна пропускна спроможність протоколу Ethernet при використовуванні кадрів мінімальної довжини складає 46 х 8/67.2 = 5.48 Мб/с.
Реальна пропускна спроможність за призначеними для користувача даними в мережі може бути тільки менше приведеного вище значення 5.48 Мб/с (для кадрів даного розміру). Відношення реальної пропускної спроможності сегменту, каналу або пристрою до його ефективної пропускної спроможності називається коефіцієнтом використання (utilization) сегменту, каналу або пристрою відповідно.
Ефективна пропускна спроможність істотно відрізняється від номінальної пропускної спроможності протоколу, що говорить про необхідність орієнтації саме на ефективну пропускну спроможність при виборі типу протоколу для того або іншого сегменту мережі. Наприклад, для протоколу Ethernet ефективна пропускна спроможність складає приблизно 70% від номінальної, а для протоколу FDDI - близько 90%.
Пропускна спроможність протоколу часто вимірюється і в кількості кадрів, переданих в секунду. неважко підрахувати, що для протоколу Ethernet ця характеристика для кадрів мінімальної довжини складає 14880 К/с. Зрозуміло, що при вимірюванні пропускної спроможності в кадрах в секунду, немає змісту розмежовувати номінальну і ефективну пропускну спроможність.
Майже всі протоколи канального рівня локальних мереж підтримують одну фіксовану номінальну пропускну спроможність: Ethernet - 10 Мб/с, TokenRing - 16 Мб/с (4 Мб/с може підтримуватися для сумісності із старим устаткуванням), FDDI, FastEthernet і 100VG-AnyLAN - 100 Мб/с. Тільки протокол АТМ може працювати з різними номінальними бітовими швидкостями - 25, 155 і 622 Мб/с, хоча перехід від однієї швидкості до іншої вимагає заміни мережних адаптерів або інтерфейсів комутаторів або маршрутизаторів.
Тому, якщо для поліпшення роботи мережі ми хочемо варіювати номінальною пропускною спроможністю протоколу, то для цього нам буде потрібно замінювати один протокол на іншій - міра можлива, але вимагає значних матеріальних і фізичних витрат.
Вплив розміру кадру і пакету на продуктивність мережі
Розмір пакету може істотним чином вплинути на ефективну пропускну спроможність протоколу, а значить і на продуктивність мережі. З'ясуємо на прикладі, як зміниться ефективна пропускна спроможність протоколу Ethernet, якщо замість кадрів мінімальної довжини при обміні даними використовуватимуться кадри максимальної довжини з полем даних в 1500 байт, як це визначено в стандарті.
Загальна довжина кадру разом з преамбулою, заголовком і контрольною сумою складе в цьому випадку 8+14+1500+4 = 1526 байт або 12208 біт. Час передачі такого кадру складе 1220.8 мкс, а період повторення кадрів - 1220.8 +9.6 = 1230.4 мкс.
Ефективна пропускна спроможність при цьому рівна (1500 х 8)/1230.4 = 9.75 Мб/с.
Отриманий результат говорить про те, що при збільшенні розміру пакету ефективна пропускна спроможність протоколу Ethernet істотно, майже в 2 рази, збільшилася - з 5.48 Мб/с до 9.75 Мб/с (мал. 2.2). Аналогічне зростання характерне для всіх протоколів і це говорить про те, що розмір пакету - один з тих параметрів, які найбільшою мірою впливають на продуктивність мережі.
Розмір пакету конкретного протоколу звичайно обмежений максимальним значенням поля даних (MaximumTransferUnit, MTU), визначеним в стандарті на протокол.
Протоколи локальних мереж мають наступні значення MTU: Ethernet, Fast Ethernet - 1500 байт; TokenRing 16 - 16 Кбайт (звичайно за умовчанням встановлюється значення 4K, але його можна збільшити); FDDI - 4Kбайта; 100VG-AnyLAN - 1500 байт при використовуванні кадрів Ethernet і 16K при використовуванні кадрів TokenRing; ATM - 48 байт.
Протоколи верхніх рівнів, починаючи з мережевого, інкапсулюють свої пакети в кадри протоколів канального рівня, тому обмеження, які існують на канальному рівні, є загальними обмеженнями максимального розміру пакету для протоколів всіх рівнів.
Необхідно відзначити, що підвищення розміру кадру збільшує пропускну спроможність мережі тільки у тому випадку, коли дані в мережі рідко спотворюються або втрачаються, тобто при стійкій, надійній роботі мережі. В іншому випадку збільшення розміру пакету може привести не до збільшення, а до зниження пропускної спроможності, оскільки мережа повторно передаватиме великі порції інформації. Для кожного рівня спотворень даних можна підібрати раціональний розмір пакету, для якого пропускна спроможність мережі буде максимальною.
Максимальний розмір пакету тільки створює передумови для підвищення пропускної спроможності, оскільки від додатків залежить, чи буде використана дана максимальна величина поля даних чи ні. Якщо, наприклад, додаток веде роботи з базою даних і пересилає на сервер SQL-запити, одержуючи у відповідь по одному короткому запису, то максимальний розмір поля даних в 4 або 16 Кбайт ніяк не допоможе підвищити пропускну спроможність мережі. При зверненні ж додатку до файлового серверу для пересилки мультимедійного файлу розміром в декілька мегабайт наявність можливості пересилати файл частинами по 16К безумовно підвищить пропускну спроможність мережі в порівнянні з варіантом пересилки файлу частинами по 1500 байт.
Настройка розміру порцій даних, що пересилаються, звичайно відбувається на транспортному рівні стека протоколів і, можливо, на прикладному, якщо розробник додатку передбачив таку можливість.
Робота з пакетами великих розмірів підвищує продуктивність мережі не тільки за рахунок зменшення невигідних витрат на службову інформацію заголовка. При використовуванні великих пакетів підвищується продуктивність комунікаційного устаткування, що працює з кадрами і пакетами, тобто мостів, комутаторів і маршрутизаторів. Це відбувається через те, що при передачі одного і того ж об'єму інформації число великих пакетів, що використовуються, істотно менше ніж число маленьких, а оскільки комунікаційне устаткування витрачає певний час на обробку кожного пакету, то і тимчасові втрати просування пакетів мостами, комутаторами і маршрутизаторами при використовуванні великих пакетів будуть менше.
Призначення максимального розміру кадру в гетерогенній мережі
Продуктивність мережі може різко впасти через неузгодженість максимального розміру кадру в різних частинах складової гетерогенної мережі (мал. 2.4).
Якщо в кожній з частин такої мережі використовується свій протокол канального рівня зі своїм значенням MTU, то проблема узгодження різних значень MTU може виникнути при передачі кадрів з мережі із великим значенням MTU в мережу з меншим значенням MTU. Наприклад, при передачі кадру розміром в 2048 байт з мережі FDDI в мережу Ethernet поле даних кадру FDDI не поміщається в полі даних кадру Ethernet, максимальний розмір якого рівний 1500 байт.
Всі існуючі протоколи канального рівня локальних мереж не передбачають можливості динамічної фрагментації кадрів з подальшою їх збіркою в початковий кадр. Функції фрагментації пакетів реалізовані тільки в протоколах мережного рівня, і то не у всіх - з найпоширеніших протоколів мережного рівня тільки протокол IP підтримує функцію динамічної фрагментації. Тому при передачі кадрів між мережами з різними значеннями MTU проблему, яка виникає, можна розв'язати двома способами - або шляхом використання IP-маршрутизатора, який фрагментуватиме IP-пакети так, щоб вони уміщалися в MTU канального протоколу (мал.2.4б), або шляхом обмеження MTU у всіх складових мережах до значення, рівного мінімальному MTU по всьому набору протоколів, які використовуються в гетерогенній мережі (мал. 2.4в). В наведеному прикладі для цього адміністратора необхідно встановити у всіх мережах максимальний розмір MTU, рівний MTU мереж Ethernet, тобто 1500 байт.
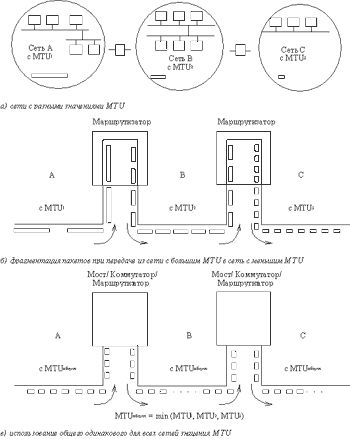

Мал. 2.4. Проблема узгодження максимального розміру кадрів в гетерогенній мережі
Вибір одного з цих варіантів не очевидний, навіть якщо оптимізація ведеться тільки по критерію продуктивності, а вартість рішення в увагу не приймається. Маршрутизатор взагалі працює не дуже швидко, а виконання фрагментації приводить до додаткового уповільнення просування пакетів. Тому при використовуванні оригінальних значень MTU в окремих частинах складеної мережі виграш в пропускній спроможності, отриманий за рахунок використання пакетів великої довжини, може бути зведений нанівець, уповільненням просування пакетів маршрутизаторами, що виконують операцію фрагментації. Якщо швидкість роботи гетерогенної мережі дуже важлива, то для досягнення максимальної продуктивності необхідно провести натурне або імітаційне моделювання двох підходів - з фрагментацією і з обмеженням MTU.
Багато додатків і протоколів прикладного рівня уміють динамічно знаходити в складовій гетерогенній мережі таке значення MTU, яке дозволяє виконувати обмін даними з необхідним сервером. Наприклад, клієнтська частина файлового сервісу мереж NovellNetWare спочатку намагається встановити зв'язок з сервером з використанням максимально можливого розміру кадру протоколу тієї мережі, до якої підключений клієнтський комп'ютер. Якщо протягом заданого тайм-ауту клієнт не одержує відповіді, то він починає зменшувати розмір кадру до тих пір, поки відповіді не почнуть поступати.
В мережі Internet для зменшення перевантажень адміністратори також почали широко застосовувати подібну техніку. Замість динамічної фрагментації використовується попередня процедура з'ясування мінімального значення MTU уздовж маршруту проходження пакетів до серверу призначення. Ця процедура полягає в наступному. Пакети IP, що використовуються в процедурі визначення MTU, відправляються зі встановленим значенням ознаки DF (Don'tFragment), яка забороняє маршрутизаторам фрагментувати даний пакет навіть при неможливості інкапсулювати його в кадр канального рівня чергової мережі. У такому разі маршрутизатори повертають вузлу-відправнику повідомлення по протоколу ICMP "Потрібна фрагментація, а біт DF встановлений". Вузол-відправник, отримавши таке повідомлення повинен зменшити розмір пакету, що відправляється, і знов спробувати передати його вузлу призначення зі встановленим бітом DF, і так до тих пір, поки повідомлення про неможливість доставки не перестануть приходити від маршрутизаторів, що знаходяться на шляху проходження. Після цього вузол-відправник може почати передачу даних кадрами такого розміру, який не вимагає фрагментації ні в одній з складових мереж. Така техніка, звана PathMTUDiscovery (дослідження MTU на шляху проходження), прийнята як стандартна в новій версії протоколу IP - IPv6, з метою звільнення маршрутизаторів від додаткової роботи по фрагментації.
При використовуванні протоколів, що не уміють фраментувати пакети, таких як IPX, техніка дослідження MTU є єдино можливої для організації стійкої роботи в складових гетерогенних мережах.
Час життя пакету
Параметр, який визначає, як довго може подорожувати пакет по складеній мережі, є в багатьох протоколах мережного рівня. В протоколі IP цей параметр називається Time-To-Live, TTL (Час життя), а в протоколі IPX - Distance (Відстань). Цей параметр використовується для того, щоб маршрутизатори, оброблювальні заголовки мережного протоколу, мали інформацію про те, як довго переміщався пакет по мережі до того, як прибув в даний маршрутизатор. Якщо пакет подорожує по мережі дуже довго, то є велика вірогідність, що він з якихось причин "заблукав". Причинами некоректного переміщення пакетів по мережі можуть бути невірні значення таблиць маршрутизації в деяких маршрутизаторах, які у свою чергу є слідством помилок адміністраторів при ручному формуванні таблиць, або недосконалістю протоколів обміну маршрутної інформації. Пакети, що "заблукали", видаляються маршрутизаторами з мережі для того, щоб на них даремно не витрачалася частина пропускної спроможності каналів і маршрутизаторів.
В протоколі IP поле TTL встановлюється вузлом-відправником в деяке ненульове значення, а маршрутизатори при просуванні пакету зменшують його, звичайно на 1. Пакет видаляється з мережі в тому випадку, якщо після зменшення значення поля TTL стає рівним 0.
В протоколі IPX поле Distance обробляється по-іншому - вузол-відправник встановлює його в 0, а кожний маршрутизатор нарощує його на 1. Пакет видаляється з мережі при досягненні цим полем значення 16.
Початкове значення поля часу життя в мережі, що працює по протоколу IP, є параметром, який впливає на продуктивність і надійність роботи мережі, що настроюється. При збільшенні початкового значення поля TTL пакети можуть перетинати більше число проміжних мереж, отже, потенційно вірогідність успішної доставки пакету будь-якому абоненту великої мережі зростає, а, значить, продуктивність може підвищитися за рахунок зменшення частки пакетів, що не "дійшли", відкинутих по дорозі. Проте при цьому в мережі може існувати велике число пакетів, що "заблукали", які знижуватимуть продуктивність мережі.
Простих рекомендацій по вибору початкового значення поля TTL в протоколі IP не існує - це значення підлягає настройці шляхом натурного експериментування або моделювання.
Параметри квитування
Протоколи, що працюють зі встановленням з'єднання, звичайно стежать за коректністю доставки пакетів одержувачу і організовують повторні передачі спотворених або загублених пакетів. В рамках з'єднання правильність передачі кожного пакету повинна підтверджуватися квитанцією одержувача. Квитування - це один з традиційних методів забезпечення надійного зв'язку. Ідея квитування полягає в наступному.
Для того, щоб можна було організувати повторну передачу спотворених даних відправник нумерує одиниці даних, що відправляються, - пакети. Для кожного пакету відправник чекає від приймача так звану позитивну квитанцію - службове повідомлення, що сповіщає про те, що початковий пакет був отриманий і дані в ньому виявилися коректними. Час цього очікування обмежений - при відправці кожного пакету передавач запускає таймер, і якщо по його закінченню позитивна квитанція не отримана, то пакет вважається загубленим. В деяких протоколах приймач, у разі отримання пакету із спотвореними даними, повинен відправити негативну квитанцію - явна вказівка того, що даний пакет потрібно передати повторно.
Існують два підходи до організації процесу обміну позитивними і негативними квитанціями: з простоями та з організацією "вікна".
Метод з простоями вимагає, щоб джерело, яке послало кадр, чекало отримання квитанції (позитивної або негативної) від приймача і лише після цього посилало наступний кадр (або повторював спотворений). З малюнка 2.5 видно, що в цьому випадку продуктивність обміну даними істотно знижується - хоча передавач і міг би послати наступний кадр зразу ж після відправки попереднього, він зобов'язаний чекати приходу квитанції.
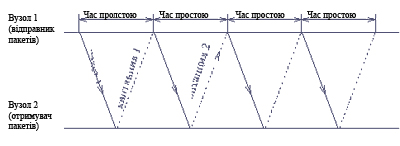

Мал. 2.5. Реалізація квитування із простоями приймача
Зниження продуктивності для цього методу корекції особливо помітний на низькошвидкісних каналах зв'язку, тобто в територіальних мережах.
Метод обміну квитанціями з простоями має один параметр - величину тайм-ауту очікування квитанції. При відправці чергового пакету зводиться таймер очікування квитанції і, якщо встановлений тайм-аут закінчився, а квитанція не прийшла, то пакет або квитанції вважаються загубленим і організовуєтся вторинна передача непідтвердженого пакету (мал. 2.6).

Мал. 2.6. Вплив тайм-ауту на роботу протоколу
Величина тайм-ауту - це основний параметр настройки протоколів, що працюють у відповідності з алгоритмом простоїв джерела. Дуже маленькі значення тайм-ауту можуть викликати небажане зниження пропускної спроможності. Це може відбутися у великій складеній мережі, в якій працюють переобтяжені маршрутизатори, поступово оброблювальні потоки пакетів. Якщо затримки передачі пакетів перевершать значення тайм-ауту, то початковий вузол повторно передаватиме пакети, які насправді не були втрачені, а просто дуже повільно йшли до вузла призначення.
При виборі величини тайм-ауту повинні враховуватися швидкість і надійність фізичних ліній зв'язку, їх протяжність і багато інших подібних чинників. В протоколі TCP, наприклад, тайм-аут визначається за допомогою достатньо складного адаптивного алгоритму, ідея якого полягає в наступному. При кожній передачі засікається час від моменту відправки сегменту до приходу квитанції про його прийом (час обороту). Набуті значення часу обороту усереднюються з ваговими коефіцієнтами, що зростають від попереднього виміру до подальшого. Це робиться для того, щоб посилити вплив останніх вимірів. Як тайм-аут вибирається середній час обороту, помножений на деякий коефіцієнт. Практика показує, що значення цього коефіцієнта повинне перевищувати 2. В мережах з великим розкидом часу обороту при виборі тайм-ауту враховується і дисперсія цієї величини.
При великих значеннях тайм-ауту втрати часу, що витратився на очікування квитанції, можуть бути дуже великими і пропускна спроможність мережі може знизитися в десятки разів.
Розглянемо приклад, що ілюструє можливе зниження пропускної спроможності мережі NovellNetWare через дуже велике значення тайм-ауту часу очікування квитанцій.
Клієнт і сервер NetWare за умовчанням використовують алгоритм квитування з простоями при організації передачі файлів. Якщо на сервері і клієнті працює стек IPX/SPX, то протокол прикладного рівня NCP, що відповідає за файловий сервіс, не використовує для транспортування своїх повідомлень протокол SPX, який працює зі встановленням з'єднання, а звертається безпосередньо до протоколу IPX. Це робиться для прискорення роботи файлового сервісу, оскільки використання кожного додаткового рівня в стеку протоколів знижує загальну продуктивність стека.
Протокол IPX - це протокол дейтаграмного типа, який повторну передачу спотворених пакетів не виконує. В результаті при втраті або спотворенні даних в локальній мережі, де на нижньому рівні також працюють протоколи дейтаграммного типу (Ethernet, TokenRing і т.п.), повторна передача пакетів організовується тільки протоколом NCP, який працює по алгоритму квитування з простоєм джерела. За умовчанням протокол NCP використовує тайм-аут в 0.5 секунди, після закінчення якого виконується повторна передача пакету, на який не прийшла квитанція.
Розглянемо на прикладі, наскільки може знизитися пропускна спроможність мережі NetWare при значенні тайм-ауту в 0.5 секунди і рівні втрачених і спотворених пакетів всього в 3%.
На малюнку 2.7 показані тимчасові діаграми передачі файлу між сервером і клієнтом в двох випадках - при ідеально працюючій мережі, коли пакети не спотворюються і не втрачаються, і в мережі з 3% рівнем загублених і спотворених пакетів.
Нехай в обох випадках між клієнтом і сервером передається файл розміром в 240 000 байт. Файл передається за допомогою протоколу IPX із службовим заголовком в 30 байт і протоколу Ethernet з розміром службового заголовка в 26 байт (з урахуванням преамбули). Розмір службового заголовка самого протоколу NCP складає 20 байт.
Нехай файл передається частинами по 1000 байт. Всього для передачі файлу буде потрібно 240 пакетів.
Розмір кадру Ethernet, що переносить 1000 байт файлу, який передається, складе 1000+20+30+26 = 1076 байт або 8608 біт.
Розмір квитанції NCP, яка підтверджує отримання пакету, рівний 10 байтам, що дає розмір кадру Ethernet, що переносить квитанцію в 86 байт (разом з преамбулою) або 688 біт.
Припустимо, що час обробки одного пакету на клієнтській стороні складає 650 мкс, а на сервері - 50 мкс.
В цих умовах час одного циклу передачі чергової частини файлу в ідеальній мережі складе 860.8 + 68.8 +650 + 50 = 1629.6 мкс.
Загальний час передачі файлу в 240 000 байт складе при цьому 240х1629.6 = 0.391 секунди, а ефективна пропускна спроможність мережі - 240000/0.391 = 613810 байт/с або 4.92 Мб/с.
При втраті (незалежно від причини) 3% кадрів Ethernet повторна передача кадру починається тільки після закінчення тайм-ауту в 0.5 сек. Всього таких випадків за час передачі файлу буде 240х0.03 = 7. Отже, час передачі файлу зросте на 7х0.5 = 3.5 сек, а загальний час передачі файлу складе 0.391 + 3.5 = 3.891 сек. Пропускна спроможність мережі при цьому стає рівною 240000/3.891 = 61680 байт/с або 0.49 Мб/с.
Таким чином, за наявності в мережі NetWare всього 3% втрачених або спотворених пакетів пропускна спроможність цієї мережі знижується в 10 разів.
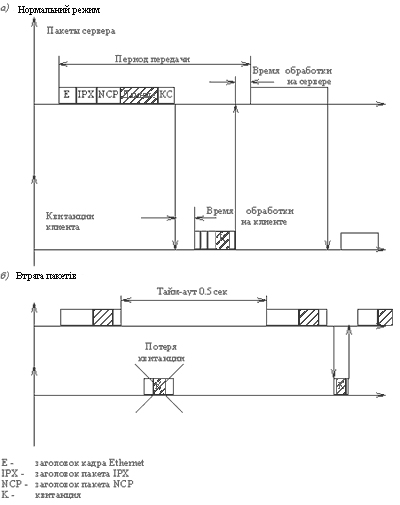

Мал. 2.7. Вплив втрат пакетів на продуктивність мережі
В другому методі - методі ковзаючого вікна - для підвищення коефіцієнта використання лінії джерелу дозволяється передати деяку кількість пакетів в безперервному режимі, тобто в максимально можливому для джерела темпі, без отримання на ці пакети у відповідь квитанцій (мал. 2.8).
 Мал. 2.8. Квитування з передачею "непідтверджених пакетів"
Мал. 2.8. Квитування з передачею "непідтверджених пакетів"
Кількість пакетів, які дозволяється передавати таким чином, називається розміром вікна. Малюнок 2.9 ілюструє даний метод для розміру вікна в 8 пакетів.

Мал. 2.9. Обмін квитанціями в режимі вікна
Цей алгоритм називають алгоритмом ковзаючого вікна. Дійсно, при кожному отриманні квитанції вікно переміщається (ковзає), захоплюючи нові дані, які дозволяється передавати без підтвердження.
Алгоритм ковзаючого вікна має два параметри, які налаштовуються, - розмір вікна і час тайм-ауту очікування приходу квитанції. Обидва параметри впливають на пропускну спроможність мережі. В мережах з рідкісними спотвореннями і втратами пакетів доцільно встановлювати великі значення вікна і тайм-ауту, в ненадійних мережах потрібно працювати з меншими значеннями як вікна, так і тайм-ауту.
Багато протоколів використовують механізм ковзаючого вікна для підвищення своєї пропускної спроможності. До них відносяться такі популярні протоколи як LAP-B, LAP-D і LAP-M сімейства HDLC, що використовуються в територіальних мережах, протокол V.42, що працює в сучасних модемах, протоколи SPX, TCP і багато протоколів прикладного рівня.
Особливість реалізації алгоритму квитування в протоколі TCP полягає в тому, що хоча одиницею передаваних даних у протоколу TCP є сегмент (інша назва пакету), вікно визначено на безлічі нумерованих байт неструктурованого потоку даних, що поступають з верхнього рівня і буферизованих протоколом TCP.
Як квитанція одержувач сегменту посилає у відповідь повідомлення (сегмент), в яке поміщає число, на одиницю перевищуюче максимальний номер байта в отриманому сегменті. Якщо розмір вікна рівний W, а остання квитанція містила значення N, то відправник може посилати нові сегменти до тих пір, поки в черговий сегмент не потрапить байт з номером N+W. Цей сегмент виходить за рамки вікна, і передачу у такому разі необхідно припинити до приходу наступної квитанції.
Особливістю протоколу TCP є також адаптивна зміна величини вікна. В переважній більшості інших протоколів розмір вікна встановлюється адміністратором і самим протоколом в процесі його роботи не змінюється. Варіюючи величину вікна, можна вплинути на завантаження мережі. Чим більше вікно, тим більшу порцію непідтверджених даних можна послати в мережу. Якщо мережа не справляється з навантаженням, то виникають черги в проміжних вузлах-маршрутизаторах і в кінцевих вузлах-комп'ютерах.
При переповнюванні приймального буфера кінцевого вузла "переобтяжений протокол" TCP, відправляючи квитанцію, поміщає в неї новий, зменшений розмір вікна. Якщо він зовсім відмовляється від прийому, то в квитанції вказується вікно нульового розміру. Проте навіть після цього додаток може послати повідомлення на що відмовився від прийому порт. Для цього, повідомлення повинне супроводжуватися поміткою "терміново". В такій ситуації порт зобов'язаний прийняти сегмент, навіть якщо для цього доведеться витіснити з буфера дані, що вже знаходяться там.
Після прийому квитанції з нульовим значенням вікна протокол-відправник час від часу робить контрольні спроби продовжити обмін даними. Якщо протокол-приймач вже готовий приймати інформацію, то у відповідь на контрольний запит він посилає квитанцію з вказівкою ненульового розміру вікна.
Іншим проявом перевантаження мережі є переповнювання буферів в маршрутизаторах. В таких випадках вони можуть централізовано змінити розмір вікна, посилаючи управляючі повідомлення деяким кінцевим вузлам, що дозволяє їм диференційований управляти інтенсивністю потоку даних в різних частинах мережі.
Порівняння мережних технологій по продуктивності: Ethernet, TokenRing, FDDI, 100VG-AnyLAN, FastEthernet, ATM
В цьому розділі підводяться деякі підсумки розгляду впливу різних параметрів протоколів канального рівня на пропускну спроможність мережі, а також приводяться результати одного експериментального порівняння протоколів в не завантаженій мережі.
Необхідно відзначити, що окрім такого критерію як пропускна спроможність, при виборі протоколу звичайно враховується і ряд інших міркувань, що іноді роблять більший вплив на кінцевий вибір, ніж результуюча пропускна спроможність мережі. Найважливішими чинниками, які потрібно брати до уваги при виборі протоколу, крім його впливу на пропускну спроможність мережі, є: Перспективність протоколу. Бажано мати впевненість, що вибраний вами протокол не спіткає доля протоколу ARCnet (або близького до нього стандарту 802.4), який при непоганих технічних показниках зійшов нанівець через відсутню підтримку з боку більшості виробників комунікаційного устаткування. Перспективність протоколу важко прогнозувати, тому можна орієнтуватися на чинник, що розглядається наступним. Кількість компаній, підтримуючий даний протокол. Для прикладу порівняємо два нові високошвидкісні протоколи - FastEthernet і 100VG-AnyLAN. Якщо перший підтримують практично всі виробники устаткування для локальних мереж (більше 100 відомих компаній), то протокол 100VG-AnyLAN підтримують тільки 30 виробників. Тому ризик при переході на протокол 100VG-AnyLAN більш великий, ніж при переході на протокол FastEthernet. Відмовостійкість протоколу. Далеко не у всі протоколи вбудовані процедури тестування коректності роботи мережі і автоматичного відновлення працездатності після відмов. Контроль доставки пакетів адресату і повторна передача спотворених і втрачених пакетів - це один з рівнів відмовостійкості, яким може володіти протокол. На жаль, велика частина протоколів канального рівня локальних мереж не виконує ці функції, а контролем працездатності кабельної системи і апаратури, і автоматичним відновленням працездатності мережі після відмов може похвалитися тільки протокол FDDI. Вартість устаткування, що реалізовує даний протокол. Цей чинник - один з головних, що забезпечили переважання протоколу Ethernet в локальних мережах і стримуючих розповсюдження технології АТМ. Вартість - важливий козир в руках прихильників технології FastEthernet, що успадковувала від 10 Мб Ethernet'а простоту алгоритмів і, відповідно, мінімальну вартість серед всіх протоколів локальних мереж. Підтримка трафіку реального часу. У зв'язку з необхідністю передачі по одній і тій же мережі традиційного комп'ютерного трафіку, слабо чутливого до затримок, і мультимедійного трафіку - голосу, відеоданих і т.п., погано переносячого затримки пакетів навіть в декілька мілісекунд, від протоколу може бути потрібно здатність пріоритезації чутливого до затримок трафіку, який є трафіком реального часу. В цьому відношенні протоколи Ethernet і FastEthernet поступаються своїм конкурентам, оскільки вони не розрізняють класи трафіку. Протоколи FDDI і 100VG-AnyLAN розрізняють трафік двох класів - звичайний і високопріоритетний і передають пріоритетні кадри в першу чергу. Самим вчиненим відносно підтримки різних типів трафіку є протокол АТМ, який сьогодні розрізняє 5 типів трафіку - від комп'ютерного з невідомою пропускною спроможністю до голосового трафіку з постійною середньою бітовою швидкістю.
Якщо ж повернутися до проблеми вибору протоколу канального рівня по критерію максимізації пропускної спроможності мережі, то самими впливаючими параметрами протоколу в цьому відношенні будуть наступні: номінальна пропускна спроможність протоколу (бітова швидкість передачі кадру); максимально допустимий розмір поля даних кадру; номінальний час доступу до середовища передачі даних.
Часто вважається, що найбільш значимим чинником є номінальна пропускна спроможність і що протокол з великим її значенням завжди приводить до більшої пропускної спроможності мережі.
Проте це далеко не завжди вірно. Результуюча пропускна спроможність мережі складається під впливом багатьох параметрів і часто найзначущішим є розмір поля даних кадру або ж час доступу до середовища. Для підтвердження цього явища приведемо результати експериментального порівняння пропускної спроможності мережі при використовуванні в ній протоколів Ethernet, TokenRing і FDDI, відмінних як номінальною пропускною спроможністю, так і максимальним розміром поля даних і номінальним часу доступу до середовища.
Експериментальна мережа полягала всього з двох вузлів - клієнтського комп'ютера і серверу, тому чинник очікування доступу до середовища через її завантаження тут не досліджувався.
Очевидно, що час виконання запиту на клієнтській і серверній машині не повинне істотно перевищувати час передачі даних запиту по мережі, інакше параметри протоколу канального рівня будуть малозначними чинниками експерименту. В експериментах часи виконання запитів варіювалися для оцінки їх впливу на результати.
Досліджувався вплив на час реакції: номінальної пропускної спроможності, максимально допустимого розміру поля даних кадру, номінального часу доступу до середовища передачі даних.
Чинник номінальної пропускної спроможності
Збільшення пропускної спроможності підвищує продуктивність мережі, хоча часто і не в такому ступені, як це очікується. На малюнку 2.10а показано, як підвищується продуктивність мережі при переході від номінальної пропускної спроможності 10 Мб/с протоколу Ethernet до номінальної пропускної спроможності 16 Мб/с протоколу TokenRing залежно від часу виконання додатку. З малюнка видно, що коли час виконання додатку перевищує 5 мс, то очікуваний виграш в продуктивності буде менше ніж 5%. Але навіть тоді, коли час виконання додатку нехтує мало в порівнянні з часом передачі запиту і відповіді по мережі, виграш в продуктивності складає всього 30%, хоча номінальна пропускна спроможність зростає на 60%. Для того, щоб з'ясувати вплив на продуктивність тільки чинника пропускної спроможності, цей графік був отриманий в припущенні однакової довжини пакетів і однакового часу доступу до середовища для обох протоколів.
Чинник розміру пакету
Різні протоколи характеризуються різними максимально допустимими довжинами пакетів. Наприклад, Ethernet допускає в пакеті поле даних, яке несе призначену для користувача інформацію завдовжки до 1024 байта, відповідно TokenRing 4 Мб/с - 4096 байт, TokenRing 16 Мб/с - 16384 байти, FDDI - 4096 байт.
На малюнку 2.10б показана залежність підвищення продуктивності мережі при переході від пакетів 1024 байти протоколу Ethernet до пакетів 4096 протоколу TokenRing 16 Мб/с. Ясно, що при цьому діє і чинник підвищення пропускної спроможності, але як видно з малюнка 2.10а, цей чинник діє набагато слабше. Дійсно, при нульовому часі виконання додатку загальний виграш від дії цих двох чинників складає 190%, тоді як при збільшенні тільки пропускній спроможності продуктивність збільшилася всього на 30%.

Мал. 2.10. Вплив різних чинників на продуктивність
Чинник номінального часу доступу до середовища
Час доступу до середовища - більш значний чинник, ніж пропускна спроможність, хоча і менш важливий, ніж розмір пакету. Малюнок 2.10в показує, що приріст продуктивності при переході від протоколу Ethernet до протоколу TokenRing 16 Мб/с є негативним для всіх точок кривої. Цей несподіваний результат означає, що в цих умовах Ethernet дійсно перевершує по продуктивності TokenRing, хоча останній і перевершує його по пропускній спроможності в 1.6 рази. Для виключення впливу розміру пакету даний аналіз був зроблений для пакетів в 1024 байти, які можуть передаватися обома протоколами. Відношення часу доступу до середовища протоколу TokenRing до відповідного часу протоколу Ethernet було прийнято рівним 5. Малюнок 2.10г показує, що перехід від протоколу TokenRing до FDDI може привести не до прискорення, а до уповільнення обміну при передачі великих файлів (через зменшення поля даних пакету FDDI).
Порівняння протоколів IP, IPX і NetBIOS по продуктивності
Пропускна спроможність протоколів мережного і транспортного рівнів (протокол NetBIOS і його модифікація NetBEUI в строгому значенні не відносяться до мережного рівня, оскільки не оперують з поняттям "номер мережі", ці протоколи швидше можна віднести до транспортного і представницького рівнів) багато в чому залежить від протоколу канального рівня, над яким працюють ці протоколи. Тому порівнювати протоколи мережного і транспортного рівнів потрібно в припущенні, що вони використовують один і той же протокол канального рівня, наприклад, Ethernet або FDDI.
Вимірювання, проведені в реальних мережах, показують, що найповільнішим протоколом локальних мереж є протокол IP. Його порівняно низька пропускна спроможність є платнею за його універсальність, тобто здатність об'єднувати практично всі існуючі мережні технології - Ethernet і X.25, ATM і FrameRelay і т.п. Універсальність протоколу IP багато в чому забезпечується незалежною схемою адресації вузлів, коли незалежно від локальної адреси вузлу довільним чином привласнюється IP-адреса єдиного формату, ніяк не пов'язаного з форматом локальної адреси. Відповідність IP-адрес локальним адресам вузлів встановлює спеціальний протокол дозволу адрес ARP (AddressResolutionProtocol), який в локальних мережах використовує для цієї мети широкомовні запити.
Протокол IPX використовує як номер вузла ту ж локальну адресу вузла, що і протоколи канального рівня, а саме, його МАС-адресу. Тому протокол IPX не вимагає залучення додаткового протоколу типу ARP при передачі пакетів. В результаті пропускна спроможність мережі при використванні протоколу IPX звичайно вище ніж при використовуванні протоколу IP. Крім того, використання ARP вводить новий етап обробки пакету, використання широкомовного трафіку саме по собі знижує пропускну спроможність мережі, оскільки підвищує ступінь завантаження сегментів мережі. Питання впливу широкомовного трафіку на продуктивність мережі більш детально розглядається в наступному розділі.
Протокол NetBIOS строго орієнтований на роботу в локальних мережах, що не розділяються на частини маршрутизаторами. Тому його розробники не стали вводити такого поняття як "мережа" або "номер мережі", обмежившися використанням для комп'ютерів МАС-адрес і символьних імен. Протокол NetBIOS може працювати в двох режимах - дейтаграмному і зі встановленням з'єднання. В останньому випадку він займається відновленням загублених і спотворених кадрів протоколу канального рівня, що потенційно підвищує пропускну спроможність мережі, оскільки переносить процедури востановления на більш низький рівень в порівнянні з прикладним, як у разі використання стека NovellNetWare.
Протокол NetBIOS широко використовує широкомовний трафік - в даному випадку він використовується для встановлення відповідності між символьними іменами комп'ютерів і МАС-адресами. Тому продуктивність мережі, що використовує протокол NetBIOS, може знижуватися через засмічення каналу, що розділяється, службовим широкомовним трафіком.
В цілому, в мережах невеликих розмірів пропускна спроможність при використанні протоколів IPX і NetBIOS буде вище, ніж при використовуванні протоколу IP. Проте, при збільшенні розмірів мережі і особливо кількості комп'ютерів в мережі, вплив широкомовного трафіку може значно понизити доступну для призначених для користувача даних смугу пропускання, і використання протоколу IP буде переважно. Крім того, необхідно враховувати тенденції розвитку протоколу IP. В новій версії цього протоколу - IPv6, процес упровадження якої вже почався, протокол ARP перестане застосовуватися, оскільки як IP-адреса вузла використовуватиметься локальна адреса, як це робиться в протоколі IPX.
Перейти до Засоби аналізу та оптимізації мереж
